Access Services
There are two ways to make a domain crawl available for users: either by deploying and supporting an access system internally (usually Wayback or a variant) or by utilizing a hosted instance supported and maintained by IA, but potentially designed in accordance with a partner’s website. The first method is dependent upon the custodial institution and its resources and capabilities. The latter version is something that IA has done for domain-scale crawling partners and examples are provided below.
Wayback Portal
- Access to content from specific domains held within the Internet Archive’s global web archive.
- Ability to include Internet Archive’s Save Page Now function, which allow users to add a webpage or individual URL for archiving. This functionality will mirror that currently available via the Wayback Machine.
- In addition to the traditional search box, other access points can be developed, such as screenshots that point towards the most visited or linked-to websites or specific topics, subjects, or categories of websites found within a specific domain.
Some examples:
- Fully hosted: https://www.webharvest.gov/ – we (IA) designed, built, and maintain this website as part of our web archiving of all U.S. Congressional websites through a contract with the U.S. National Archive (NARA).
- Partially hosted: http://eotarchive.cdlib.org/ – all full-text search and replay of archived pages is handled by IA, though CDL hosts the website front-end portal.
- Local portals: https://archive-it.org/blog/post/creating-local-portals-to-web-archive-collections/ – this blog post details how partner institutions provide local portals built on our web archiving services.
- National Library integrations: we are currently developing a branded, onsite-access-only, ccTLD-bounded access interface for The German National Library and can provide more details upon request.
Search functionalities
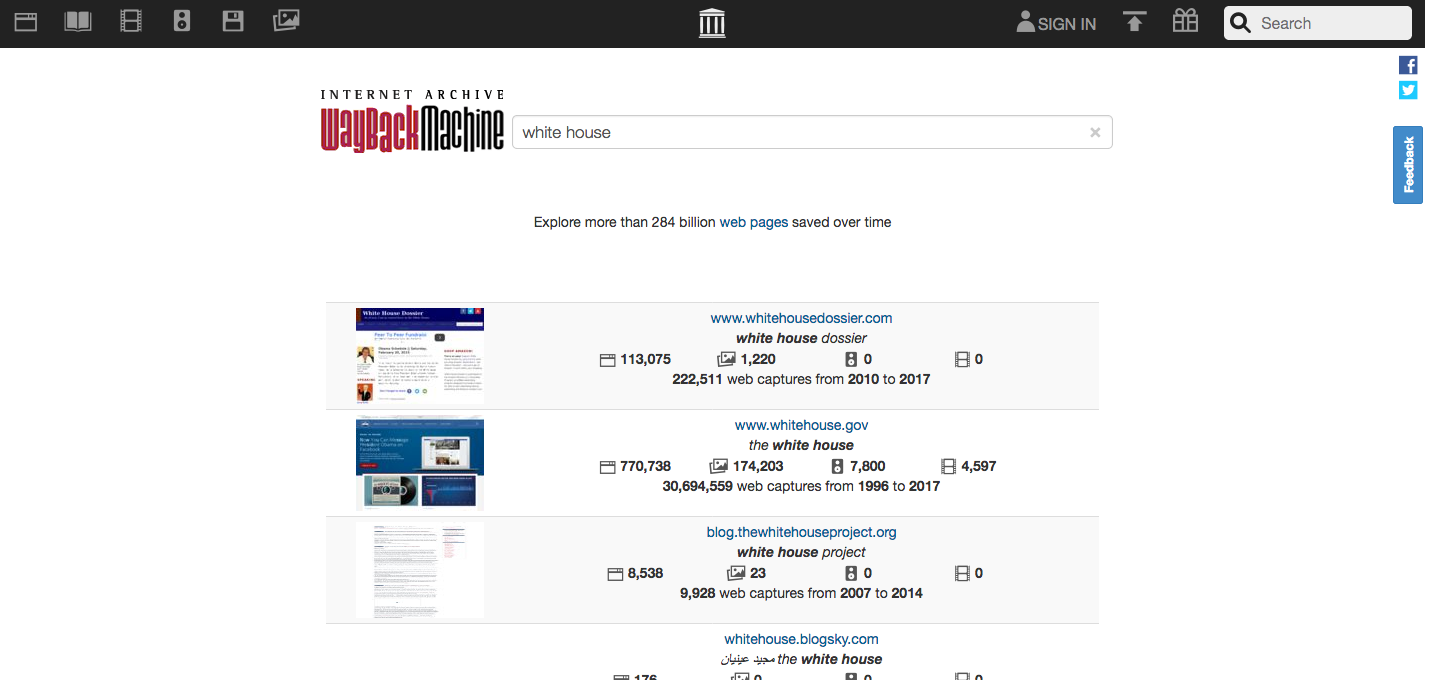
Site search: Includes both URL search as well as keyword search. Keywords are derived from the anchor text of all webpages linking to a host. Site search functionality is currently viewable in the new Wayback Machine at https://web.archive.org.
Media search: Media search takes an archived web media resource (such as an image) and “tokenizes” its URL name by turning the filename into individual words which then become the text for a search index. An example of URL tokenization search can be seen in GifCities, where the search engine is powered by the words in the (in this case) .gif filenames. Tokenization provides a way to allow for search of resources that themselves may contain no text.
All search indexing at the Internet Archive is done using ElasticSearch, an open-source and widely utilized search tool. ElasticSearch is used across the Internet Archive for both web and non-web search and includes and monitored and maintained search cluster for high performance and easy addition of multiple indicies.