ARCH
ARCH (Archives Research Compute Hub) is a platform for building research collections, analyzing them computationally, and generating datasets from terabytes and even petabytes of data. ARCH supports the open publication and preservation of user-generated datasets created from thousands of libraries, archives, and memory organizations worldwide, giving researchers, students, and information professionals the power to study and understand digital collections in new ways.
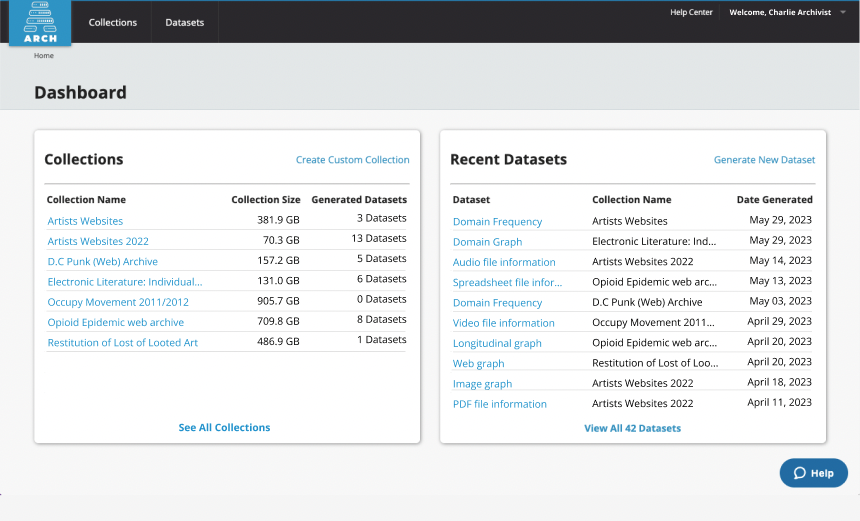
Features
Build: Curate a research collection for analysis using primary source web, text, and image digital collections.
Access: Generate more than a dozen different datasets (full text, images, pdfs, graph data, etc.) from primary source digital collections with the click of a button. Download generated datasets in-browser or via API.
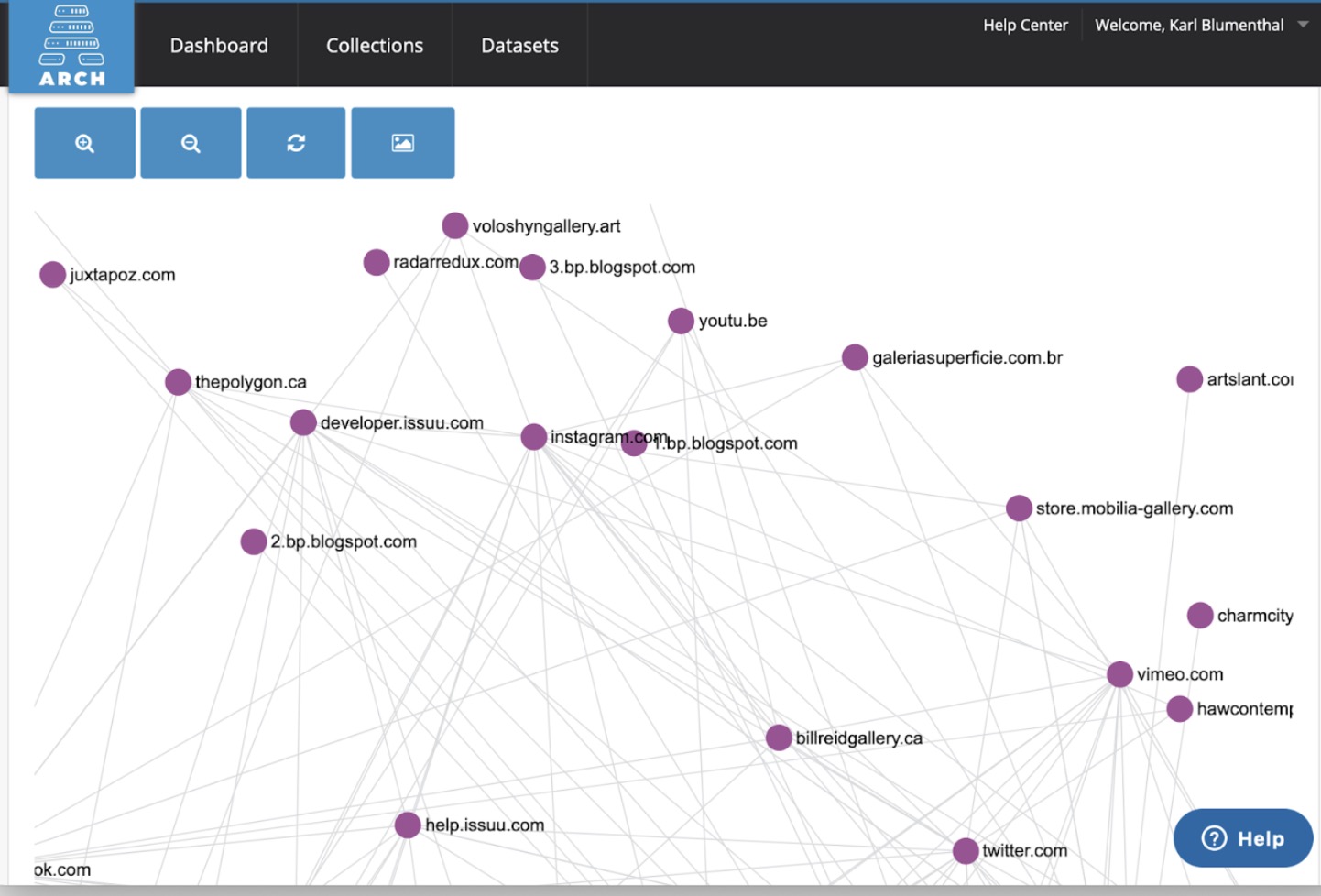
Analyze: Easily work with research-ready datasets, both through in-browser visualizations in ARCH and in interactive computational tools like Jupyter Notebooks, Google CoLab, Gephi, and Voyant, and others.
Publish and Preserve: Publish datasets with one click on archive.org, where they can be openly accessed and shared. All published datasets are preserved in perpetuity.
Support: Technical support, online training, and extensive help center documentation are all available.
Streamline Data-Driven Research
ARCH leverages the Internet Archive’s non-profit infrastructure and open-source tools to streamline computational use of digital collections. Librarians, collection managers, and educators can provide ARCH to their researchers and students in order to facilitate sophisticated research processes that would otherwise require coding/scripting skills and significant computing resources.
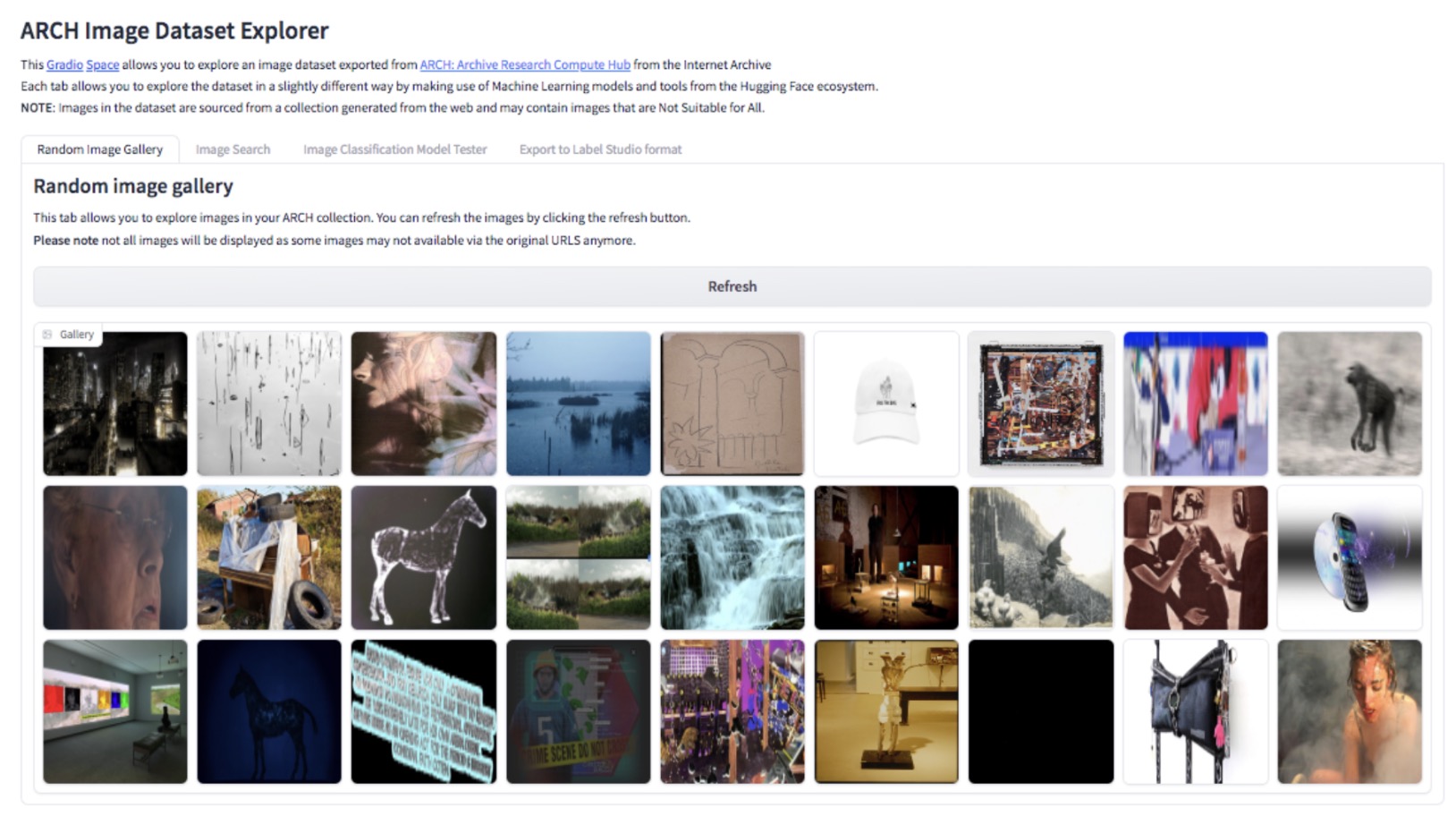
Screenshot of an image search engine for the Artists Websites web archive collection, created by Hugging Face with the ARCH image graph dataset (source)
Background
ARCH was made possible in part by funding from the Mellon Foundation and via a long-running collaboration with the Archives Unleashed project of the University of Waterloo and York University.
Interested? Contact us!
For pricing and service offering inquiries, please fill out our interest form. For other questions or to talk to ARCH staff, contact us at arch@archive.org.